
In the next few articles are going to learn everything about Modern System Designs. This series of articles will be equivalent to Grokking Mordern system design course for engineers and managers.
Abstraction is used to hide background details or any unnecessary implementation of the data so that users only see the required information. It is one of the most important and essential features of object-oriented programming.
System Design: Pre-defined functions are similar to data abstraction.
Data Abstraction is a process of hiding unwanted or irrelevant details from the end user. It provides a different view and helps in achieving data independence which is used to enhance the security of data.
Levels of abstraction for DBMS
Database systems include complex data structures. In terms of retrieval of data, reducing complexity in terms of usability of users, and order to make the system efficient, developers use levels of abstraction that hide irrelevant details from the users. Levels of abstraction simplify database design.
Mainly there are three levels of abstraction for DBMS, which are as follows −
- Physical or Internal Level
- Logical or Conceptual Level
- View or External Level
Physical or Internal Level
It is the lowest level of abstraction for DBMS which defines how the data is actually stored, it defines data-structures to store data and access methods used by the database. Actually, it is decided by developers or database application programmers how to store the data in the database.
So, overall, the entire database is described in this level that is physical or internal level. It is a very complex level to understand. For example, customer information is stored in tables, and data is stored in the form of blocks of storage such as bytes, gigabytes etc.
Logical or Conceptual Level
Logical level is the intermediate level or next higher level.
It describes what data is stored in the database and what relationship exists among those data. It tries to describe the entire or whole data because it describes what tables to be created and what are the links among those tables that are created.
It is less complex than the physical level. Logical level is used by developers or database administrators (DBA). So, overall, the logical level contains tables (fields and attributes) and relationships among table attributes.
View or External Level
It is the highest level. In view level, there are different levels of views and every view only defines a part of the entire data. It also simplifies interaction with the user and it provides many views or multiple views of the same database.
View level can be used by all users (all levels’ users). This level is the least complex and easy to understand.
Remote Procedure Call (RPC)
Remote Procedure Call (RPC) is a powerful technique for constructing distributed, client-server based applications. It is based on extending the conventional local procedure calling so that the called procedure need not exist in the same address space as the calling procedure. The two processes may be on the same system, or they may be on different systems with a network connecting them.
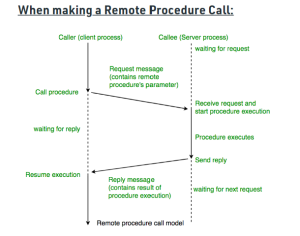
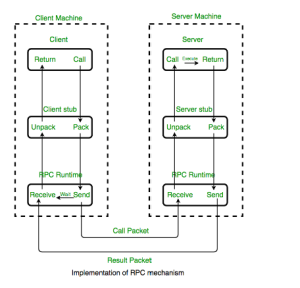
ADVANTAGES :
- RPC provides ABSTRACTION i.e message-passing nature of network communication is hidden from the user.
- RPC often omits many of the protocol layers to improve performance. Even a small performance improvement is important because a program may invoke RPCs often.
- RPC enables the usage of the applications in the distributed environment, not only in the local environment.
- With RPC code re-writing / re-developing effort is minimized.
- Process-oriented and thread-oriented models supported by RPC.
Consistency:
It can be defined as –
Each replica Node has the same view of data at a given time
Each read request gets the most recent view of the write.
Types of Consistency:
- Eventual consistency
- Causal Consistency
- Sequential Consistency
- Strict Consistency/Linearizability
Eventual Consistency:
The weakest form of consistency
All replicas will eventually return the same value for read requests. May take time, one replica may return older value but high availability. Example. Video views may differ from user to user if requesting nodes are different.
Ensure high availability
DNS uses eventual consistency
Cassandra uses eventual consistency. High available, No SQL
Causal Consistency:
Preserves the order of causally-related(dependent) operation. Operation (A <- B) will update at together, Operation C may not update at the same time and may return an older value.
Does not ensure the ordering of operations that are non-causal
Weak consistency but stronger than eventual consistency
Eg: comment replies
Sequential Consistency:
Stronger than causal consistency
Preserves the ordering specified by each client’s program.
A program running in a sequentially consistent and distributed environment will behave as if all the instructions are interleaved in a sequential manner. This means multiple execution paths are possible and allowed, provided that the instruction order of each thread of execution is preserved.
Eg: FB posts of friends. Sequential for a particular friend but overall.
Or
Let’s say we have a program with two threads that is run in a distributed system with 2 processors:
Thread 1: print “Hello\n” ; print “world \n”
Thread 2: print “Hi! \n”
In sequential consistency, ‘Hello’ should print before ‘world’ as it will execute the instructions of processor 1 and processor 2 in a sequential order while preserving the instruction.
Strict Consistency/Linearizability
Strongest consistency model.
Read requests from any replicas to get the latest write value. Availability may be weaker.
Eg: Password update of bank account
Failure Model:
The way in which failure may occur in order to provide an understanding of its effects.
Omission Failure:
Process or communication channel fails to perform actions that they are supposed to do.
Process Failure: Crash, Not responding
Communication failure: Loss of msg b/w sending and buffer. Or buffer or receiver.
Arbitrary Failure:
Any type of error can occur in either process, channel, or both. This can be due to hacking, or virus worm.
Process failure: Not performing steps or doing unintended steps.
Channel failure: Msg – corrupt, duplicate etc.
Timing Failure:
Only applicable to a synchronous distributed system.
Clock: It affects the process. – Local clock exceeds the drift rate bound.
Performance:
Process: Exceed the bounds on interval b/w two steps.
Channel: Message delay exceeding set bound.
Reliability Failure:
Validity: Msg in the outgoing buffer is delivered to the incoming buffer
Integrity: Correct msg is delivered
Threat: Prevention from malicious users.
Thank you for reading. We hope this gives you a good understanding. Explore our Technology News blogs for more news related to the Technology front. AdvanceDataScience.Com has the latest in what matters in technology daily.



{kind=link}